ClickHouse and ZooKeeper Troubleshooting
ClickHouse and ZooKeeper Troubleshooting
Problem: You’re experiencing data inconsistencies, replication failures, or image pull issues related to ClickHouse and ZooKeeper components.
Solution: This comprehensive guide covers the most critical ClickHouse and ZooKeeper issues based on real production troubleshooting experience.
Critical Understanding: ClickHouse replication issues can cause inconsistent UI behavior, where refreshing the page shows different data each time. This is typically caused by UUID mismatches between replicas.
Understanding ClickHouse in LangFuse
Before troubleshooting, it’s important to understand that LangFuse uses ClickHouse for high-performance analytics queries on trace data. For a complete understanding of the database architecture, see the Database Architecture Guide.
Key Components:
- 3 ClickHouse replicas for high availability
- ZooKeeper ensemble for coordination
- 13 tables/views that must exist on all replicas
ClickHouse Replication Synchronization Issues
Problem Symptoms
UI Behavior:
- Inconsistent data displayed on UI refresh (different trace counts each time)
- “Empty traces” appearing intermittently
- Internal server errors:
traces.filterOptions,traces.byIdWithObservationsAndScores - Sessions and Observations tables showing malformed column names
Visual Indicators:
When ClickHouse replication issues occur, the LangFuse UI may show degraded functionality:
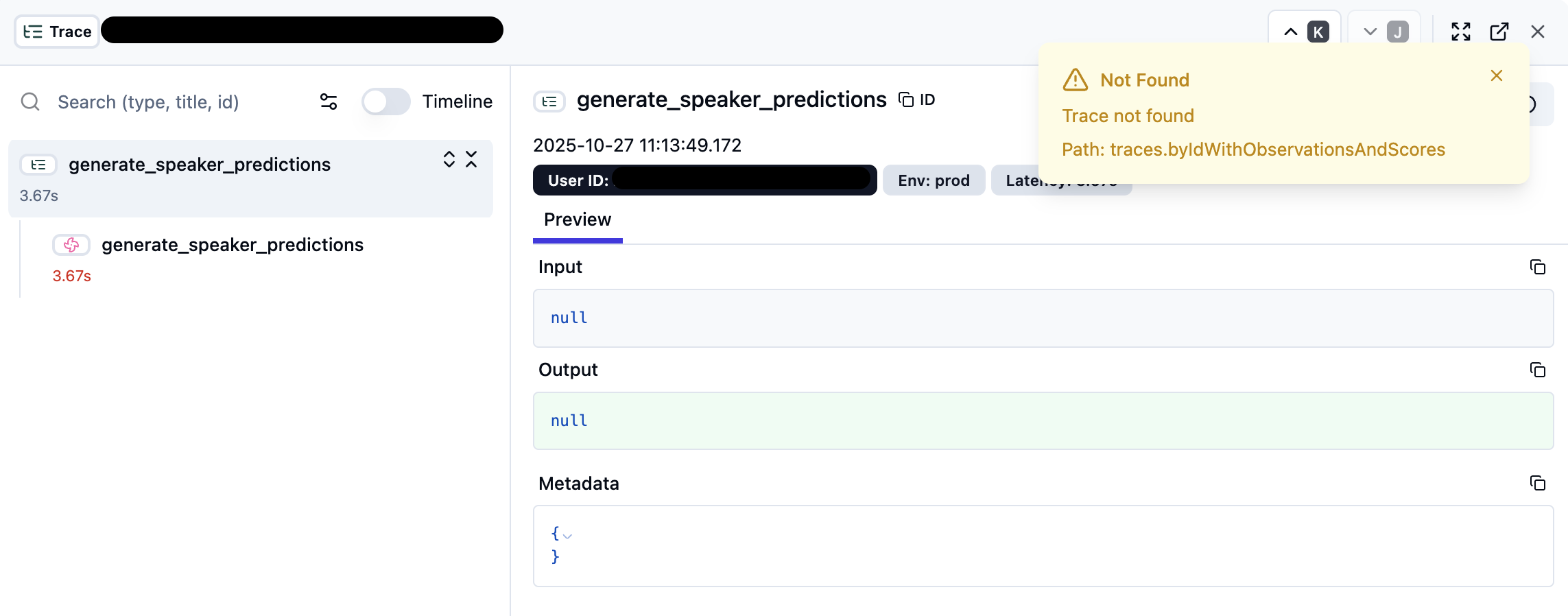
Key UI Indicators:
- Trace Loading Issues: Traces may show “Not Found” errors or fail to load completely
- Null Input/Output: Trace data appears as
nullvalues instead of actual content - Empty Metadata: Trace metadata sections show empty JSON objects
{} - Timeline Disruption: Trace timeline may be incomplete or missing spans
Root Cause Analysis
Primary Cause: After recreating ClickHouse replicas with fresh PersistentVolumeClaims (PVCs), new replicas initialize tables with different UUIDs than the original replica. This creates multiple isolated replication groups instead of one unified cluster.
Example of Broken State:
✗ BROKEN STATE:
- shard0-0: UUID bd05a9b1-9dc0-417f-93b8-22fbda0e61ba (34,264 traces)
- shard0-1: UUID bcdf1671-85dc-4f0c-ac38-94b3c43a20e0 (34,109 traces)
- shard0-2: UUID bcdf1671-85dc-4f0c-ac38-94b3c43a20e0 (34,184 traces)Each replica contains different data, and the load balancer randomly directs queries to different replicas, causing inconsistent UI behavior.
Diagnostic Commands
Check Replication Status:
# Verify current replication health
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT table, total_replicas, active_replicas FROM system.replicas WHERE database='default'"
# Expected output: total_replicas=3, active_replicas=3 for all tablesVerify UUID Consistency:
# Check UUIDs across all replicas
for pod in langfuse-clickhouse-shard0-{0,1,2}; do
echo "=== $pod ==="
kubectl exec $pod -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT table, zookeeper_path FROM system.replicas WHERE database='default'"
done
# All replicas should show identical UUIDs in zookeeper_pathCheck Data Consistency:
# Verify row counts across replicas
for pod in langfuse-clickhouse-shard0-{0,1,2}; do
echo "$pod:"
kubectl exec $pod -n langfuse -- clickhouse-client \
--password=$PASSWORD -q "SELECT count() FROM traces"
done
# All replicas should show the same countResolution Steps
Data Safety: This procedure involves scaling down to a single replica. Ensure you identify the replica with the most complete data before proceeding.
Step 1: Scale Down to Single Replica
# Scale down to keep only the primary replica
kubectl scale statefulset langfuse-clickhouse-shard0 --replicas=1 -n langfuse
# Verify only shard0-0 is running
kubectl get pods -n langfuse | grep clickhouseKeep only shard0-0 (the replica with the most complete data) to establish a single source of truth.
Step 2: Delete Corrupted PVCs
# Remove PVCs for the corrupted replicas
kubectl delete pvc data-langfuse-clickhouse-shard0-1 data-langfuse-clickhouse-shard0-2 -n langfuse
# Verify PVCs are deleted
kubectl get pvc -n langfuse | grep clickhouseStep 3: Clean ZooKeeper Metadata
For each table UUID, remove stale replica metadata:
# Get UUIDs from the remaining healthy replica
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT table, zookeeper_path FROM system.replicas WHERE database='default'"
# Clean up each UUID's replica metadata (replace {UUID} with actual values)
kubectl exec langfuse-zookeeper-0 -n langfuse -- zkCli.sh -server localhost:2181 \
deleteall /clickhouse/tables/{UUID}/shard0/replicas/langfuse-clickhouse-shard0-1
kubectl exec langfuse-zookeeper-0 -n langfuse -- zkCli.sh -server localhost:2181 \
deleteall /clickhouse/tables/{UUID}/shard0/replicas/langfuse-clickhouse-shard0-2Step 4: Scale Back Up
# Scale back to 3 replicas
kubectl scale statefulset langfuse-clickhouse-shard0 --replicas=3 -n langfuse
# Wait for pods to start
kubectl wait --for=condition=ready pod -l app.kubernetes.io/name=clickhouse -n langfuse --timeout=300sStep 5: Recreate Tables with Correct UUIDs
For each of the 6 replicated tables, recreate on the new replicas using the explicit UUID from shard0-0:
Get the correct UUID:
# Get the UUID for the traces table (example)
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT zookeeper_path FROM system.replicas WHERE table='traces' AND database='default'"Example for traces table:
-- Execute on shard0-1 and shard0-2
CREATE TABLE IF NOT EXISTS traces (
-- [Use the complete schema from the original table]
) ENGINE = ReplicatedReplacingMergeTree(
'/clickhouse/tables/bd05a9b1-9dc0-417f-93b8-22fbda0e61ba/shard0', -- ← Use explicit UUID from shard0-0
'{replica}',
event_ts,
is_deleted
)
PARTITION BY toYYYYMM(timestamp)
PRIMARY KEY (project_id, toDate(timestamp))
ORDER BY (project_id, toDate(timestamp), id)
SETTINGS index_granularity = 8192Repeat for all replicated tables: - observations - scores - blob_storage_file_log - project_environments - schema_migrations
Step 6: Create Supporting Objects
On both new replicas, create the supporting views and tables:
Analytics Views:
CREATE VIEW analytics_observations AS
SELECT
toStartOfHour(timestamp) as hour,
project_id,
count() as observation_count
FROM observations
GROUP BY hour, project_id;
CREATE VIEW analytics_scores AS
SELECT
toStartOfHour(timestamp) as hour,
project_id,
count() as score_count
FROM scores
GROUP BY hour, project_id;
CREATE VIEW analytics_traces AS
SELECT
toStartOfHour(timestamp) as hour,
project_id,
count() as trace_count
FROM traces
GROUP BY hour, project_id;Event Log Table:
CREATE TABLE event_log (
timestamp DateTime,
event_type String,
project_id String,
data String
) ENGINE = MergeTree
ORDER BY (timestamp, project_id);Materialized Views:
CREATE MATERIALIZED VIEW project_environments_observations_mv TO project_environments AS
SELECT
project_id,
'observations' as metric_type,
count() as value
FROM observations
GROUP BY project_id;
CREATE MATERIALIZED VIEW project_environments_scores_mv TO project_environments AS
SELECT
project_id,
'scores' as metric_type,
count() as value
FROM scores
GROUP BY project_id;
CREATE MATERIALIZED VIEW project_environments_traces_mv TO project_environments AS
SELECT
project_id,
'traces' as metric_type,
count() as value
FROM traces
GROUP BY project_id;Step 7: Verify Replication
# Check replication health
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT
table,
replica_name,
is_leader,
total_replicas,
active_replicas,
queue_size,
log_max_index,
log_pointer
FROM system.replicas
WHERE database='default'
ORDER BY table"
# Verify data consistency across all replicas
for pod in langfuse-clickhouse-shard0-{0,1,2}; do
echo "$pod:"
kubectl exec $pod -n langfuse -- clickhouse-client \
--password=$PASSWORD -q \
"SELECT
'traces' as table, count() as row_count FROM traces
UNION ALL
SELECT 'observations', count() FROM observations
UNION ALL
SELECT 'scores', count() FROM scores"
doneImagePullBackOff Issues
Bitnami Registry Migration (Critical)
Date: August 28, 2025 - Bitnami migrated all versioned container images
Symptoms:
- Error:
docker.io/bitnami/<image>:<tag>: not found - Even “latest” tags fail for versioned images
- Working pods use cached images
- New node deployments fail
Background:
Bitnami migrated versioned container images:
- Old location:
docker.io/bitnami/* - New location:
docker.io/bitnamilegacy/*(for versioned tags) - Public catalog:
docker.io/bitnami/*(latest tags only)
Diagnostic Commands
Check Current Image References:
# Check what images are being pulled
kubectl get statefulset -n langfuse -o yaml | grep "image:"
# Test pull from bitnami (will fail for versioned tags)
kubectl debug node/<node-name> -it --image=alpine -- \
chroot /host crictl pull docker.io/bitnami/clickhouse:25.2.1-debian-12-r0
# Test pull from bitnamilegacy (should work)
kubectl debug node/<node-name> -it --image=alpine -- \
chroot /host crictl pull docker.io/bitnamilegacy/clickhouse:25.2.1-debian-12-r0Check Pod Events:
# Get detailed error information
kubectl describe pod <failing-pod> -n langfuse | grep -A 10 "Events:"
# Check which node is affected
kubectl get pods -n langfuse -o wide | grep ImagePullBackOffResolution Options
Option A: Quick Fix - Use Legacy Registry
# Update Helm deployment to use legacy registry
helm upgrade langfuse oci://registry-1.docker.io/bitnamicharts/langfuse \
-n langfuse \
--reuse-values \
--set clickhouse.image.registry=docker.io \
--set clickhouse.image.repository=bitnamilegacy/clickhouse \
--set clickhouse.zookeeper.image.registry=docker.io \
--set clickhouse.zookeeper.image.repository=bitnamilegacy/zookeeper
# Verify the update
kubectl get statefulset -n langfuse -o yaml | grep "image:" | grep bitnamilegacyOption B: Node-Specific Issues
If only specific nodes are affected:
# Check node conditions
kubectl describe node <node-name>
# Check disk space on node
kubectl debug node/<node-name> -it --image=alpine -- df -h /host
# Clean up unused images if disk pressure
kubectl debug node/<node-name> -it --image=alpine -- \
chroot /host crictl rmi --prune
# If node is consistently problematic, consider replacement
kubectl cordon <node-name>
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-dataRegistry Connectivity Issues
Symptoms: - Error: connection refused, timeout, network error - Intermittent failures - Affects external registries
Diagnostic Commands:
# Test DNS resolution
kubectl debug node/<node-name> -it --image=busybox -- nslookup docker.io
# Test network connectivity
kubectl debug node/<node-name> -it --image=busybox -- ping -c 3 registry-1.docker.io
# Check NAT Gateway status (Azure)
az network nat gateway show --name <nat-gw> --resource-group <rg>Common Causes and Solutions:
- NAT Gateway Exhaustion:
# Check SNAT port usage
az monitor metrics list \
--resource <nat-gw-id> \
--metric "SNAT Connection Count"
# Add more public IPs if exhausted
az network nat gateway update \
--name <nat-gw> \
--resource-group <rg> \
--public-ip-addresses ip1 ip2 ip3- Network Policies:
# Check for restrictive network policies
kubectl get networkpolicies -A
# Temporarily allow all egress for testing
kubectl apply -f - <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
namespace: langfuse
spec:
podSelector: {}
policyTypes:
- Egress
egress:
- {}
EOFPrevention and Monitoring
Replication Monitoring
Set up Regular Health Checks:
# Create monitoring script
cat > check_clickhouse_health.sh << 'EOF'
#!/bin/bash
echo "=== ClickHouse Replication Health ==="
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$CLICKHOUSE_PASSWORD -q \
"SELECT table, total_replicas, active_replicas,
CASE WHEN total_replicas = active_replicas THEN 'HEALTHY' ELSE 'DEGRADED' END as status
FROM system.replicas WHERE database='default'"
echo "=== Data Consistency Check ==="
for pod in langfuse-clickhouse-shard0-{0,1,2}; do
count=$(kubectl exec $pod -n langfuse -- clickhouse-client \
--password=$CLICKHOUSE_PASSWORD -q "SELECT count() FROM traces" 2>/dev/null || echo "ERROR")
echo "$pod: $count traces"
done
EOF
chmod +x check_clickhouse_health.shAutomated Monitoring:
# Run health check every 5 minutes
watch -n 300 ./check_clickhouse_health.shPrevention Best Practices
- Never delete PVCs without proper backup - Data and replication metadata are both lost
- Always verify UUID consistency after scaling operations
- Monitor replication status - Set up alerts for
active_replicas < total_replicas - Document all table UUIDs before any maintenance operations
- Use ZooKeeper cleanup before recreating replicas
Image Pull Prevention
- Pin specific image versions in Helm values
- Set up image pull monitoring and alerts
- Subscribe to registry provider announcements (Bitnami, Docker Hub)
- Implement image mirroring to private registry (ACR)
- Test image pulls on all nodes periodically
Quick Reference Commands
Emergency Diagnostics
# Quick health check
kubectl get pods -n langfuse | grep -E "(clickhouse|zookeeper)"
# Check replication status
kubectl exec langfuse-clickhouse-shard0-0 -n langfuse -- clickhouse-client \
--password=$PASSWORD -q "SELECT table, active_replicas FROM system.replicas"
# Check for image pull errors
kubectl get events -n langfuse --field-selector reason=Failed | grep -i "image"
# Test manual image pull
kubectl debug node/<node-name> -it --image=alpine -- \
chroot /host crictl pull <full-image-path>Emergency Recovery
# Force pod restart
kubectl delete pod <pod-name> -n langfuse
# Scale down/up StatefulSet
kubectl scale statefulset langfuse-clickhouse-shard0 --replicas=0 -n langfuse
sleep 30
kubectl scale statefulset langfuse-clickhouse-shard0 --replicas=3 -n langfuse
# Check Helm values
helm get values langfuse -n langfuse